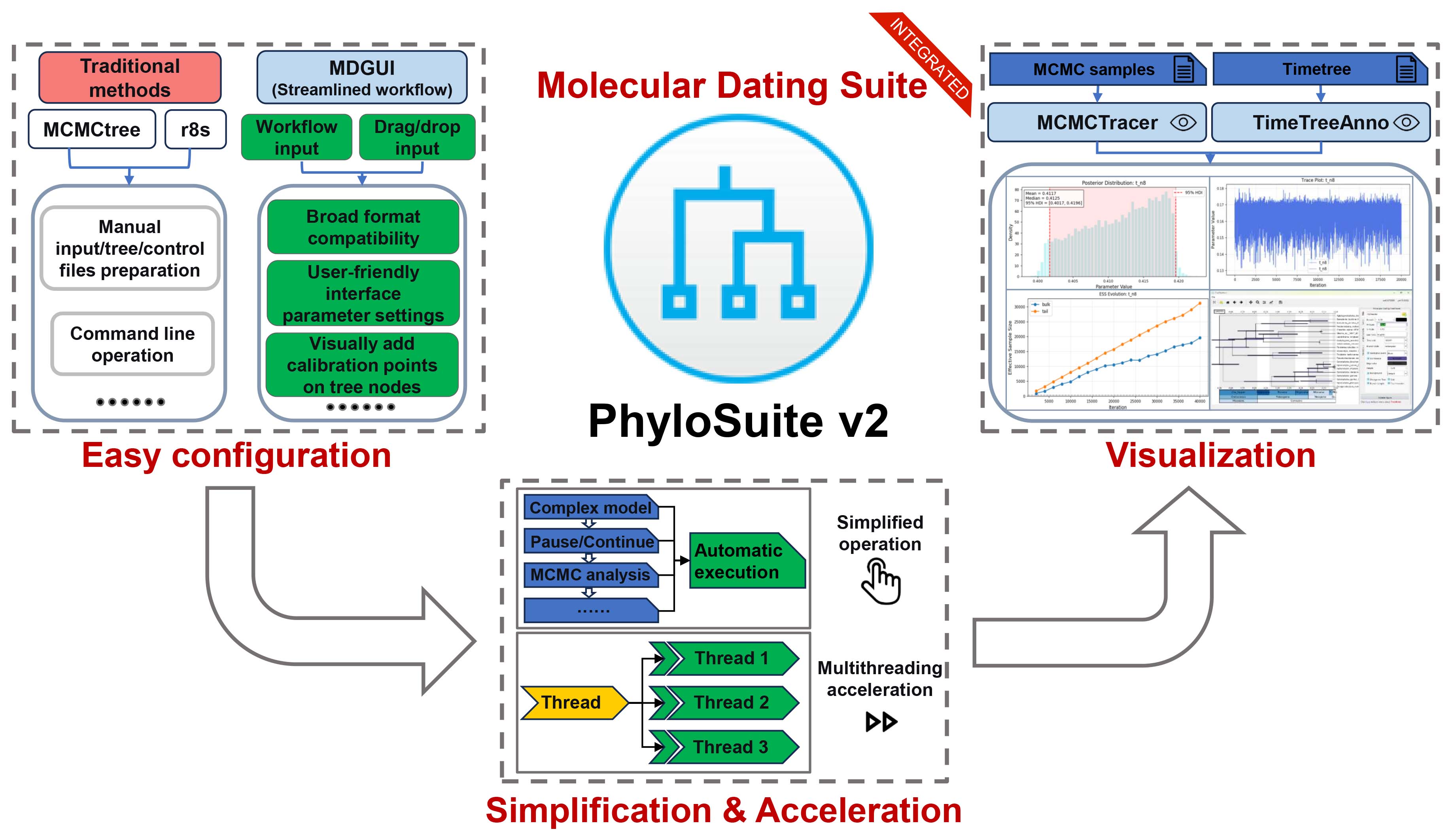
Molecular dating analysis
Tutorial videoes
The video below describes the operation of multilocus phylogeny pipeline in PhyloSuite.
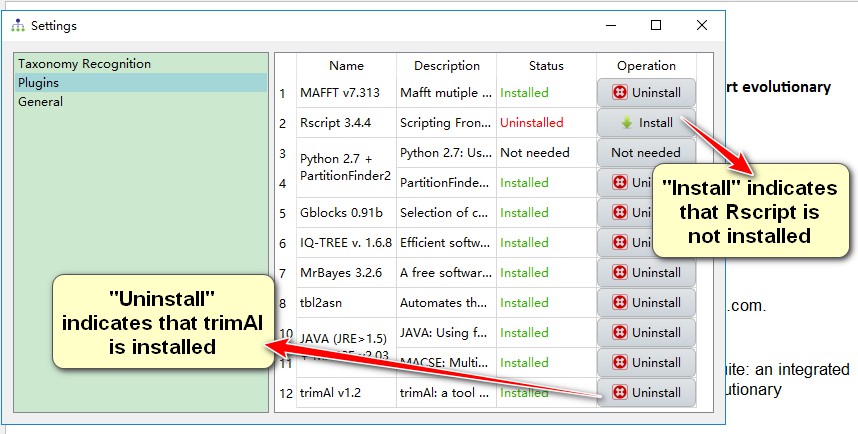
How to configure plugins
There are two ways to configure the plugins:
1. Download PhyloSuite with plugins
When using Windows and Mac OSX systems, you can download PhyloSuite_xxx_Win32/64_with_plugins.rar and PhyloSuite_xxx_Mac_with_plugins.zip from https://github.com/dongzhang0725/PhyloSuite/releases, respectively. All plugins, except Python 2.7, Perl 5, Java, Rscript, HmmCleaner and trimAl (MAC) are included.
2. Configure plugins separately
Customizing the extraction
When extracting sequences, you should use different settings for different data-types. PhyloSuite has five predefined data-types, Mitogenome, general, cox1, 16S and 18S, but you can easily add your own data-type extraction settings, suited to your data.
Here I will demonstrate the process of making the extraction settings for the mitochondrial genome data-type.
Single gene phylogeny
PhyloSuite: from data aquisition to phylogenetic tree annotation (single gene tree building)

Muti-gene phylogeny
PhyloSuite: from data acquisition to phylogenetic tree annotation (muti-gene dataset)

In order to make it easier for users to get started, here we briefly introduce the use of PhyloSuite using an example of all available Monogenea (class) (Platyhelminthes) mitochondrial genomes (mitogenomes).
Author’s Note: To save space, the contents duplicated with our single-gene tutorial will not be detailed in this article.
Five ways to import data into PhyloSuite
1. Search in the NCBI
Please see http://phylosuite.jushengwu.com/dongzhang0725.github.io/documentation/#4-3-3-1-Brief-example.
Quick start
Chinese homepage link: http://phylosuite.jushengwu.com/
1. Installation
1.1 PhyloSuite
Please see http://phylosuite.jushengwu.com/dongzhang0725.github.io/installation/.
1.2 Plugins
Please see http://phylosuite.jushengwu.com/dongzhang0725.github.io/PhyloSuite-demo/how-to-configure-plugins/.